
Claude's 1M Token Window Just Went Free
What it actually means, why it matters, and what you can do with it starting today.
Most AI announcements are noise. A new benchmark, a slightly faster model, a pricing change buried in a blog post that takes three reads to understand. You learn to filter.
This one is different.

Anthropic quietly made Claude’s one million token context window available on the free tier. No paywall. No enterprise contract. No waiting list. A million tokens, open to anyone with an account.
If you just nodded and moved on, you probably don’t have a clear sense of what a million tokens actually means in practice. Most people don’t, because the number is large enough to feel abstract. So before getting into why this matters, it’s worth making the number real.
First, Let’s Get the Numbers Right
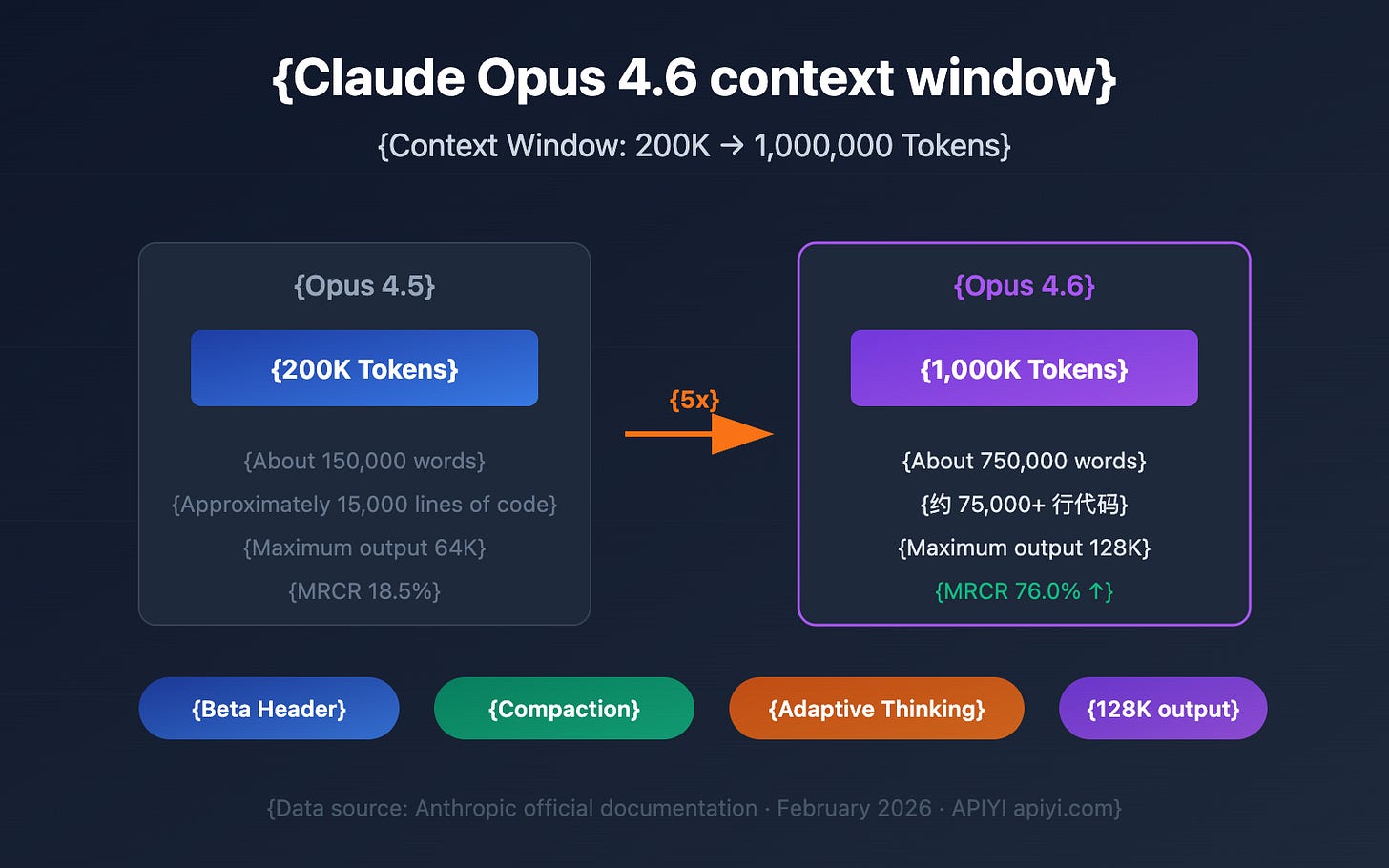
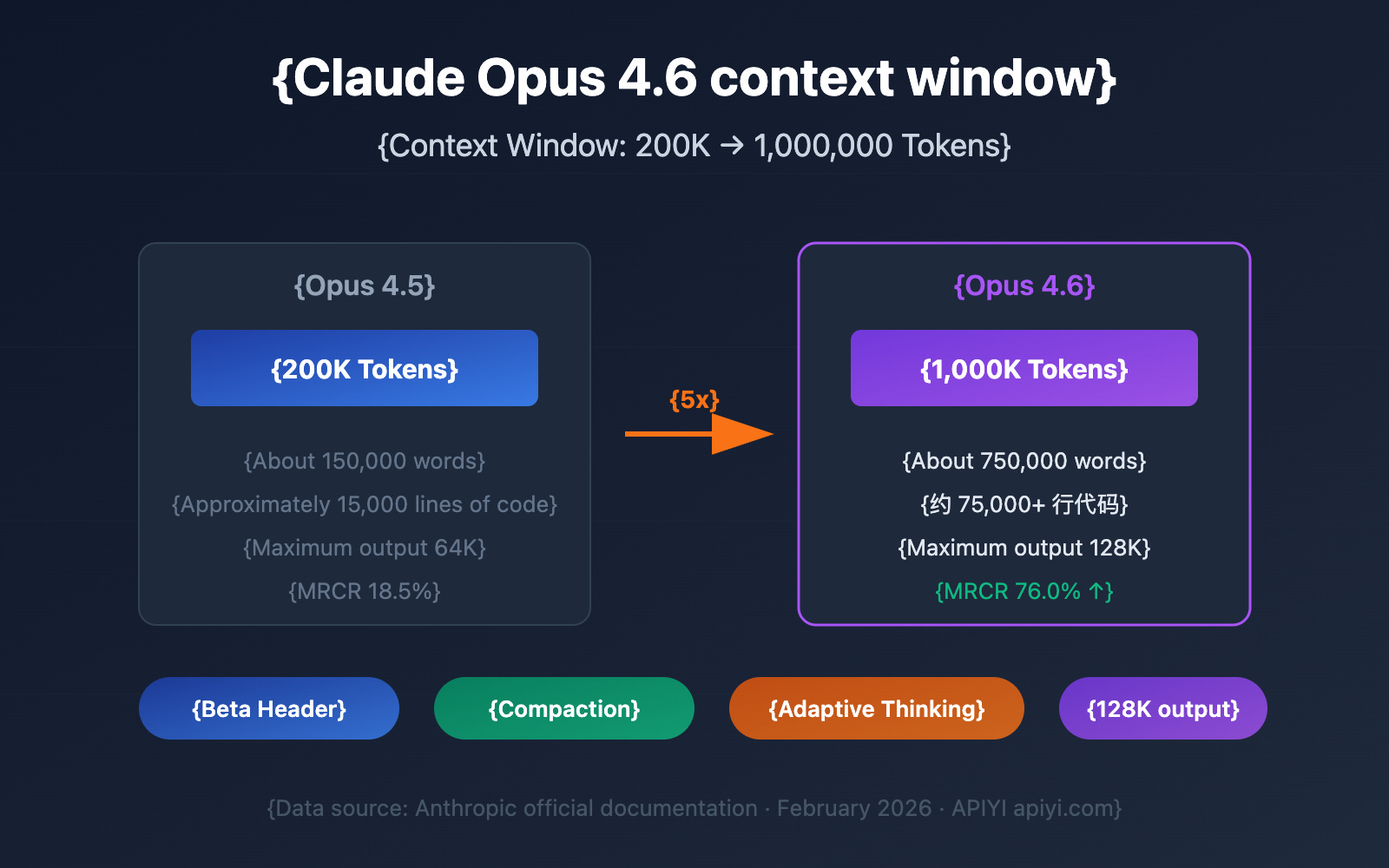
The previous standard for Claude was 200,000 tokens, which already put it ahead of most competitors. The jump to 1 million tokens isn’t just a bigger number. It’s a 5x expansion of the working memory your AI uses to understand your documents, hold reasoning chains, and maintain context across long, complex sessions.
And the pricing stays flat. A 900,000-token request is billed at the same per-token rate as a 9,000-token one.
No beta header required either. Requests over 200K tokens previously needed a special anthropic-beta header. That requirement has been silently dropped. The API just works.
For anyone who’s been building around these constraints, that last line deserves a full stop and a moment of quiet appreciation.
The Problem Nobody Talked About Enough
Here’s the thing about context limits that didn’t get enough attention in most coverage.
The advertised 200K window was never really 200K of usable space.
System prompts eat tokens. Tool definitions eat tokens. Claude Code reserves a compaction buffer of roughly 33,000 tokens (down from 45,000, a change that wasn’t even officially announced). Compaction would trigger automatically at around 83.5% capacity. So your effective, reliable working space on a 200K window was closer to 110,000 tokens before quality started to degrade.
One developer described the old reality perfectly: “Claude Code can burn 100K+ tokens searching databases, source code, and external tools. Then compaction kicks in.” You’d watch the session summarise itself, lose the thread on complex multi-step tasks, forget the edge cases you’d already worked through, and have to start rebuilding context from scratch.
The practical solution most heavy users landed on? Just run /clear and start fresh. Frequently. Which, as a strategy, completely defeats the purpose of having a large context window in the first place.
With 1M tokens, the compaction threshold moves dramatically. You’re looking at roughly 830,000 usable tokens before compaction becomes a concern. That’s not just more space. That’s a fundamentally different working session.
What a Million Tokens Actually Looks Like

Numbers are abstract. Let’s make them concrete.
1 million tokens is approximately:
The entire source code of a mid-sized production application, including tests, config files, and documentation
Every customer support ticket your company received in the last six months, read in full, at once
A 200-page legal contract plus every precedent document, exhibit, and amendment alongside it
Five complete novels worth of research, all in context simultaneously
A year’s worth of meeting transcripts, available to query without any retrieval pipeline
This isn’t hypothetical. These are the workflows that are now structurally possible for the first time without hacks, workarounds, or premium surcharges.
The Benchmark Nobody Should Skip Past
Raw context size is useless if the model can’t actually remember what’s in it.
This is the part that got buried in most coverage, and it shouldn’t have.
Anthropic published benchmarks that test recall and reasoning specifically at the 1M token mark. Opus 4.6 scores 78.3% on MRCR v2 at 1 million tokens. MRCR (Multi-Round Coreference Resolution) tests whether the model can track entities and relationships across an enormous context. Nearly 80% accuracy across a million tokens means Claude isn’t just holding the text. It’s maintaining meaningful connections between distant parts of it.
For comparison, Gemini scores 26.3% on the same benchmark. The previous best Claude scored 18.5%.
That gap is not a rounding error. That’s a structural difference in how useful the window actually is in practice. You can have the biggest RAM in the room and still think slowly if your architecture can’t use it.
Who Will Get Affected the Most
Developers and engineers are the obvious beneficiaries. The compaction problem has been a real tax on serious Claude Code usage. An engineer at Ramp described having to re-search, re-aggregate, and rebuild reasoning context every time compaction kicked in. With a 1M window, that entire overhead disappears for most real-world sessions. A 15% decrease in compaction events has already been reported since the window shipped.
Analysts and researchers can now load entire document sets, not representative samples. The difference between “I read the relevant parts” and “I read everything” shows up in the quality of synthesis, in the edge cases caught, in the conclusions you can stand behind.
Legal and compliance teams working with dense contracts and regulatory documentation can finally stop choosing between depth and breadth. Load the full contract. Load all the precedents. Ask the question once.
Autonomous agent builders get the biggest structural win. Long-running agents that need to maintain state across dozens of tool calls, search results, and intermediate reasoning steps no longer need to architect elaborate external memory systems just to compensate for a context window that was too small. The window is now the memory, for most practical purposes.
The Pricing Signal That Matters More Than the Feature
Here’s the strategic read that’s easy to miss.
Previously, long-context inference was either unavailable or came with significant pricing premiums. Building production workflows around 500K+ tokens was often economically impractical at scale. You’d architect around the pricing, not around what you actually needed.
By making 1M tokens the standard rate, Anthropic is sending a clear message: long-context inference is becoming a baseline feature, not a premium add-on.
That changes the comparison matrix for anyone evaluating AI infrastructure. You’re no longer asking “can I afford to use long context?” You’re asking “what do I want to build now that I can?”
The two questions lead to very different places.
How to Access It Right Now
Quick and clean:
Max, Team, and Enterprise plans: The 1M window is automatic with Opus 4.6 and Sonnet 4.6. No settings to change, no extra charge, no opt-in.
Pro plan: You need to opt in via
/extra-usagein Claude Code. It doesn’t come on automatically.API users: No beta header required. The
context-1m-2025-08-07header is being retired for older models by April 30, 2026. Migrate to Sonnet 4.6 or Opus 4.6 to keep the 1M window going forward.Platform availability: Live on Claude Platform, Microsoft Azure Foundry, and Google Cloud Vertex AI.
The Real Shift
Every major leap in AI capability tends to look incremental until it doesn’t.
More context means the model can see more of your actual problem before it starts answering. It means fewer lossy summaries, fewer “start fresh” interruptions, fewer architectural workarounds built to compensate for a working memory that was too small for the work at hand.
It means the gap between what you prompt and what you need gets a little smaller.
And for anyone building seriously with Claude, that gap is exactly where the interesting work happens.
A million tokens at standard pricing isn’t just a pricing update. It’s a quiet shift in what the baseline looks like. And in AI, the baseline tends to move faster than people expect.
Found this useful? Subscribe for more on AI tools, infrastructure decisions, and what actually changes when the numbers shift.
love this!!