
AI Feedback Loops: How Machines Learn From Mistakes
The Hidden Engine Behind Adaptive AI Systems

The next evolution of AI won’t come from bigger models, it will come from systems that teach themselves.
Every major leap in artificial intelligence has followed a single pattern:
models get bigger - performance improves - progress slows - someone changes the learning loop - everything jumps forward again.
GPT didn’t explode because someone added more layers.
It exploded because researchers figured out how to feed back massive amounts of human corrections, self-evaluations, and reinforcement signals into the training cycle.
The next wave of AI will push that idea much further
from models that produce answers,
to systems that actively judge their own output,
test alternatives,
and improve continuously through feedback.
This is the quiet revolution happening underneath all the GPT hype:
AI systems that learn from mistakes, not just from data.
Why Feedback Loops Matter More Than Model Size
For years, AI progress came from scale:
more data, more compute, more training.
But we’re reaching diminishing returns.
Increasing model size from 175B - 1T doesn’t give 10× improvements.
Feedback does.
Because improvement isn’t about memorization
It’s about corrections.
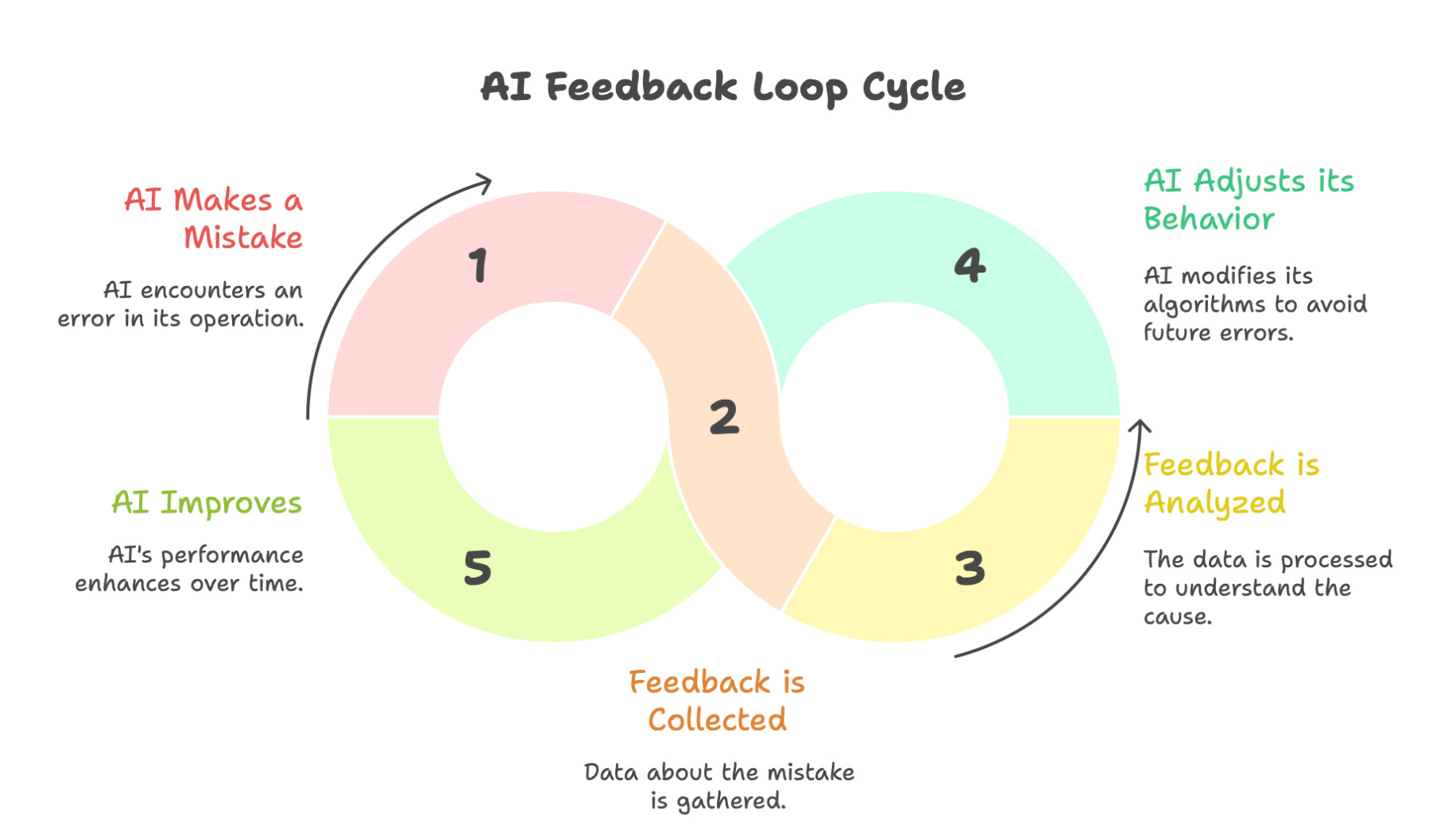
What Is an AI Feedback Loop?
An AI feedback loop is a closed learning cycle where a system:
1 makes a prediction
2 checks the result
3 measures correctness
4 adjusts behavior
5 tries again
The loop never ends.
The model constantly refines itself.
This structure appears everywhere in nature:
evolution, science, language, human learning.
Now, AI is adopting the same pattern.
ChatGPT vs Feedback AI: Real Difference
Traditional LLMs:
Prompt → Output → Done
Feedback-driven AI:
Output → Evaluate → Fix → Retry → Improve → Repeat
One gives you a paragraph.
The other gives you progress.
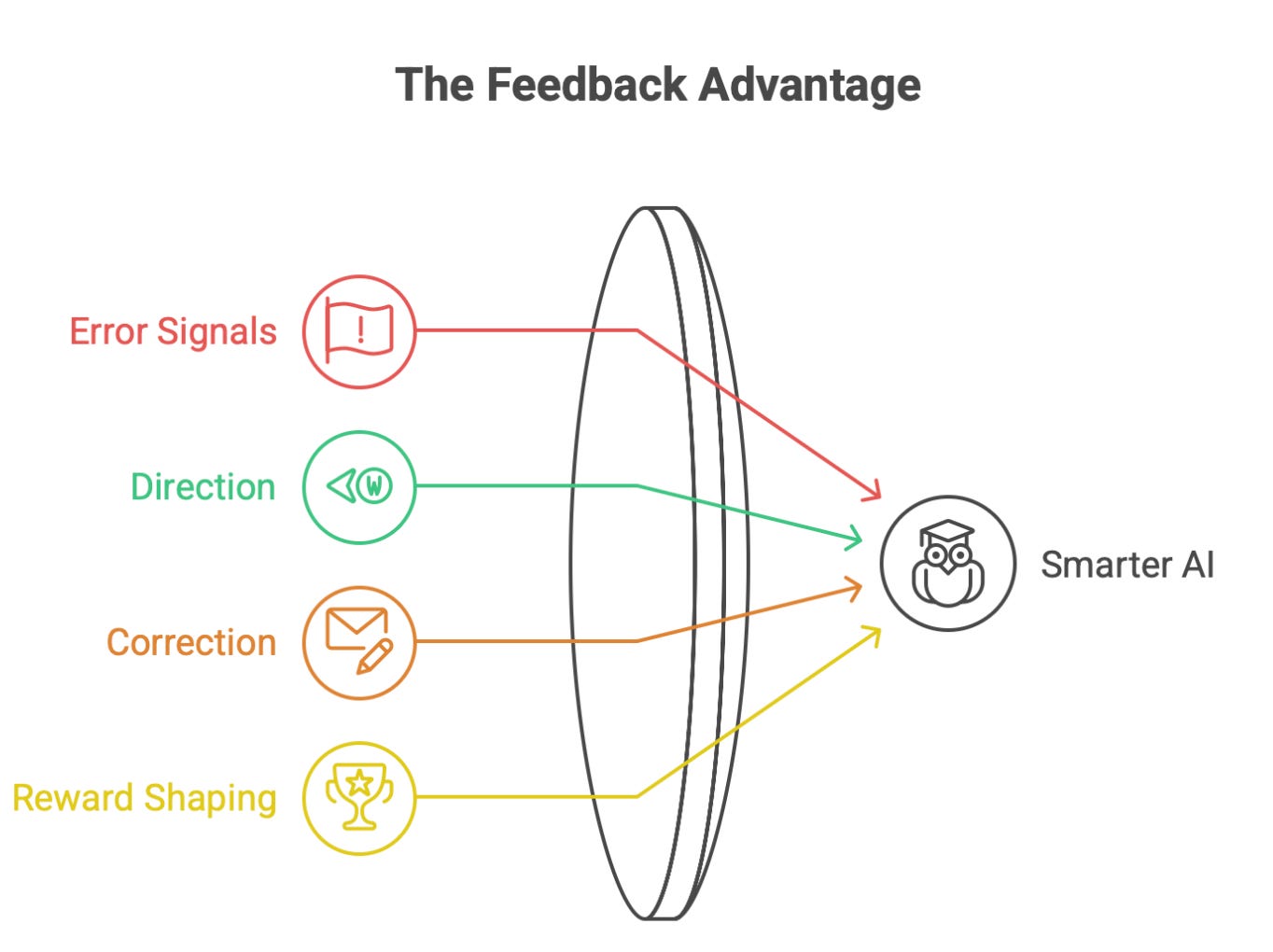
Why Feedback Makes AI Smarter
Because feedback provides something data alone cannot:
error signals
direction
correction
reward shaping
Data gives the model information.
Feedback gives the model judgment.
That’s the leap.
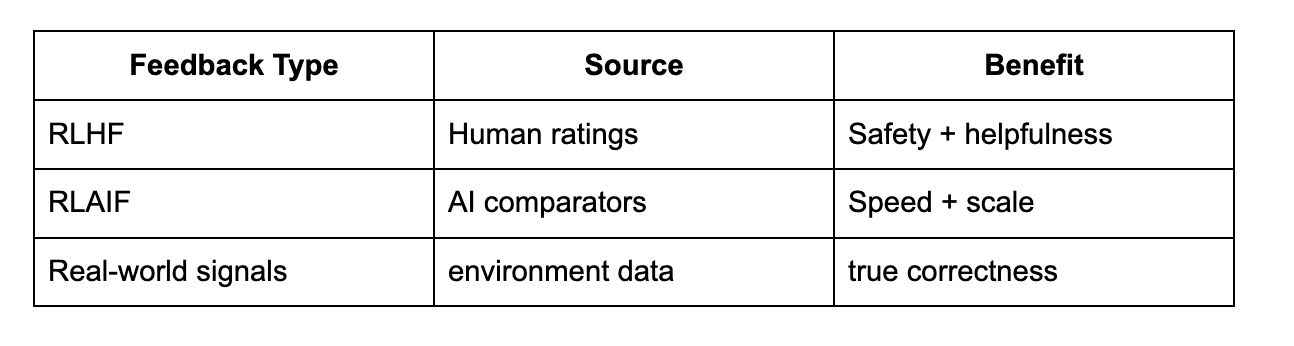
Three Types of AI Feedback Loops
1 Human Feedback (RLHF)
Humans score outputs - AI learns preferred behavior.
This built ChatGPT’s personality.
2 AI Self-Feedback (RLAIF)
Models judge each other - no humans required.
This is accelerating rapidly.
3 Real-World Feedback (Autonomous Systems)
Systems adjust based on results - not opinions.
Self-driving cars don’t ask a prompt reviewer:
They measure distance to the lane border.
Feedback Sources & Value
Why The Future Belongs to Loop-Based AI, Not One-Shot Models
One-shot models are static.
They answer once and forget everything.
Loops create systems that:
evolve
accumulate skill
correct biases
reduce hallucination
learn specific domains
personalize behavior
We’re moving from large models - adaptive models.
The Magic: Error Centered Intelligence
Humans don’t learn by doing things right.
We learn by doing things wrong
then fixing the wrong.
Now AI can do that too:
an agent writes code
code fails
agent rewrites
tests pass
knowledge persists
Failure becomes training data.
The AI Feedback Engine
Task → Output
↓
Judge/Eval
↓
Score Result
↓
Improve / Rewrite
↓
New Output
↓
Loop
The loop never rests.
Why Feedback Will Break Hallucinations
Hallucinations occur because:
the model does not know when it’s wrong.
With feedback loops:
evaluation models check claims
retrieval validates citations
reward penalizes hallucinations
Accuracy improves not through size,
but through correction cycles.
Real Example: Code Feedback Agent
Agent runs code:
compile → error → rewrite → retry
With every loop:
performance rises,
failure rate drops,
output stabilizes.
This isn’t prompting.
It’s engineering.
Why Retrieval Isn’t Enough
RAG gives LLMs knowledge.
Feedback gives them judgment.
Knowledge + judgment = intelligence.
Self-Evaluating Models Are Already Here
DeepMind, Anthropic, OpenAI all use systems where:
one model writes
another model critiques
a third model rewrites
This triangle forms a recursive improvement loop.
Feedback - Learning - Exponential Gap
Companies with strong feedback systems win.
Companies without feedback stagnate.
Two AI organizations may use the same model,
but feedback pipelines create:
domain expertise
reliability
error resilience
institutional memory
Model quality stops being the differentiator.
Learning velocity becomes the differentiator.
Feedback Loops Turn AI From a Tool - a System
Tools produce output.
Systems produce improvement.
A system that learns from mistakes
eventually outgrows its own creators.
That is the scary + exciting part.
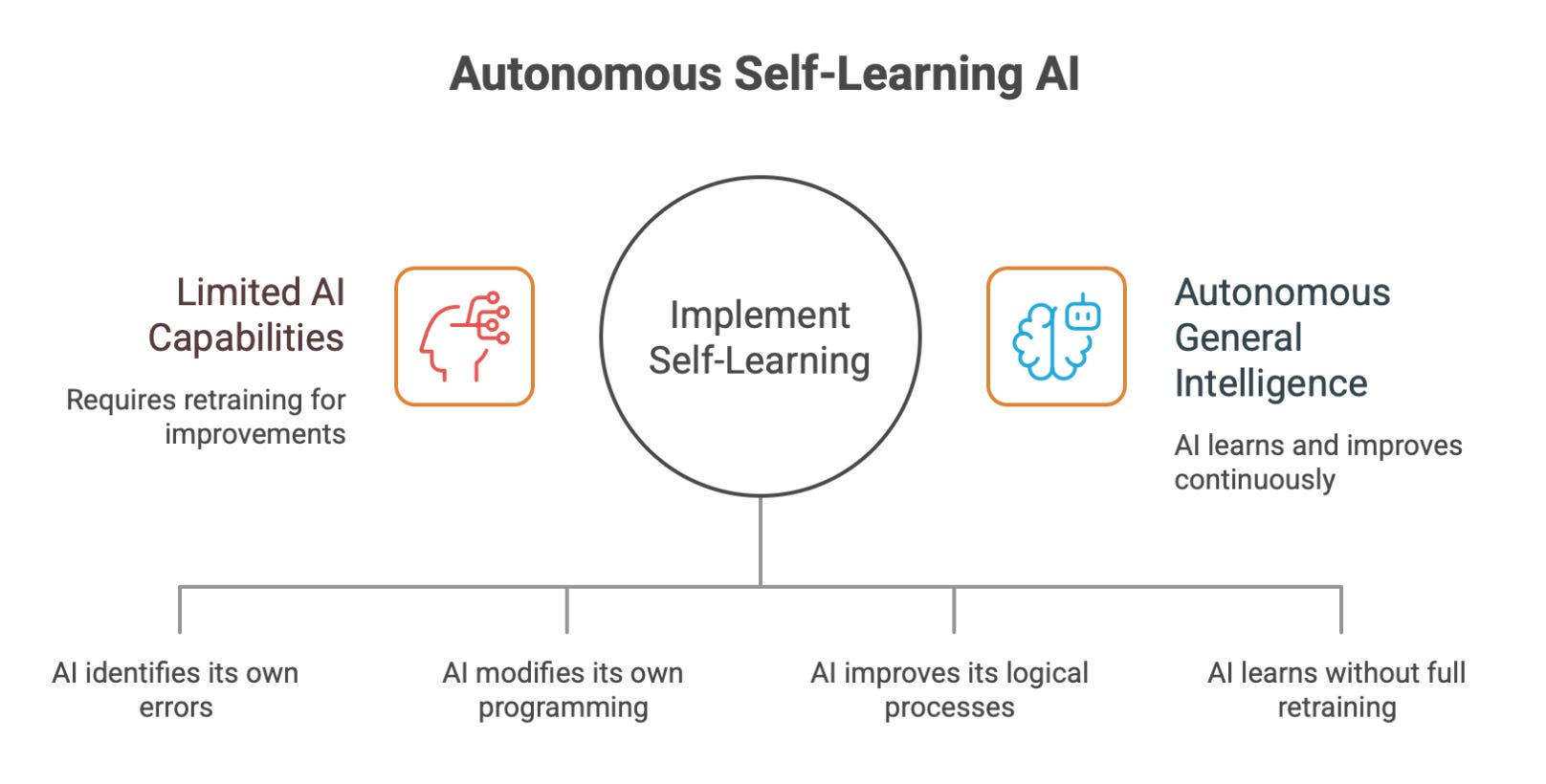
The Future: Autonomous Self-Learning AI
Combine:
agents + memory + feedback loops
and you get something new:
AI that:
detects its own failures
rewrites its own code
patches its own reasoning
improves continuously
without retraining entire weights
This is the doorway to AGI (Artificial General Intelligence).
The next era of AI is not about:
bigger datasets,
more tokens,
or trillion-parameter hype.
It is about:
feedback, correction, iteration, persistence.
Models that learn once will fall behind.
Models that learn forever will win.
The future belongs to AI systems
that learn by making mistakes - just like us.
The idea that the next AI evolution comes from systems that teach themselves, not bigger models, is spot on.
Feedback loops are where real learning happens. Static training data only takes you so far.
The shift from scale to feedback as the next improvemnt driver is spot on. I've been workign with self-evaluating code agents for the past 2 months and the iterative rewrite loops dramatically outperform single-pass generation on complex tasks. The "knowledge + judgement = intelligence" formula really captures why RAG alone feels incomplete for production systems.