
How We Stop AI From Going Off the Rails
From Chaos to Control in Intelligent Systems

The real danger in AI is not intelligence.
It’s an uncontrolled capability.
Most AI systems don’t fail because they are wrong.
They fail because nothing stops them from being wrong in the wrong way.
As AI systems move from static models to agents, workflows, and autonomous execution, a new layer becomes critical - and dangerously underdeveloped:
AI control systems.
Not ethics.
Not alignment theory.
Not “be safe” prompts.
Actual, mechanical systems that bound behavior, limit blast radius, and force recoverability when intelligence inevitably fails.
Why AI Needs Control Systems (Not Just Better Models)
Traditional software fails loudly.
Crashes
Exceptions
Broken flows
AI systems fail quietly.
Plausible but wrong answers
Confident hallucinations
Gradual behavior drift
Autonomous actions with unintended consequences
That difference changes everything.
In AI, correctness is probabilistic.
Failure is often invisible.
And by the time users notice, trust is already gone.
This is why AI systems cannot rely on:
model quality alone
prompt instructions
post-hoc monitoring
They need control by design.
What “Control” Actually Means in AI Systems
Control does not mean:
eliminating errors
preventing all autonomy
forcing determinism
Control means:
Designing systems so that when AI is wrong,
it is wrong in predictable, bounded, and recoverable ways.
This is the same philosophy used in:
aviation systems
nuclear reactors
financial trading systems
AI is now complex enough to require the same discipline.
The Control Problem Unique to AI
AI systems differ from traditional systems in four critical ways:
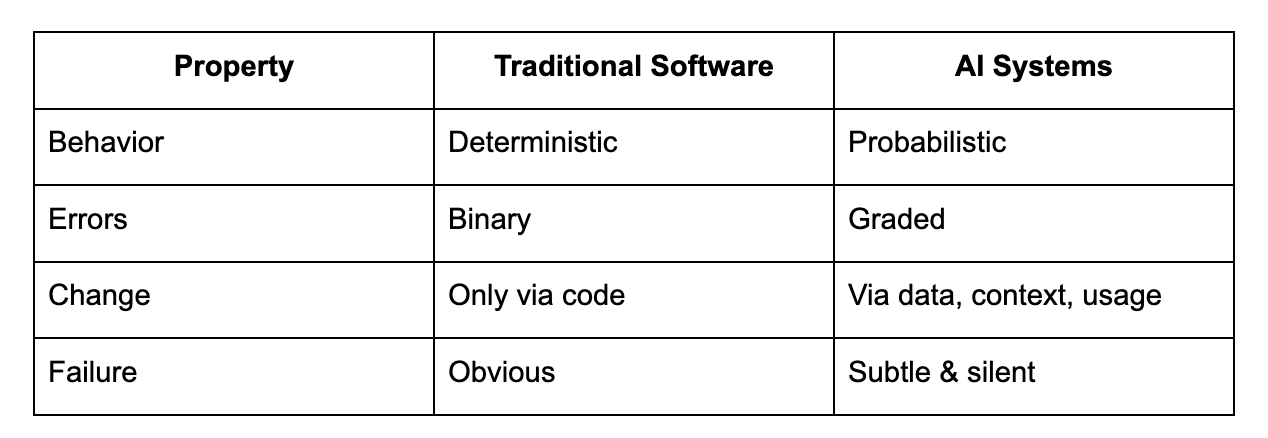
Because of this, instruction-based control breaks down quickly.
You cannot prompt your way to safety.
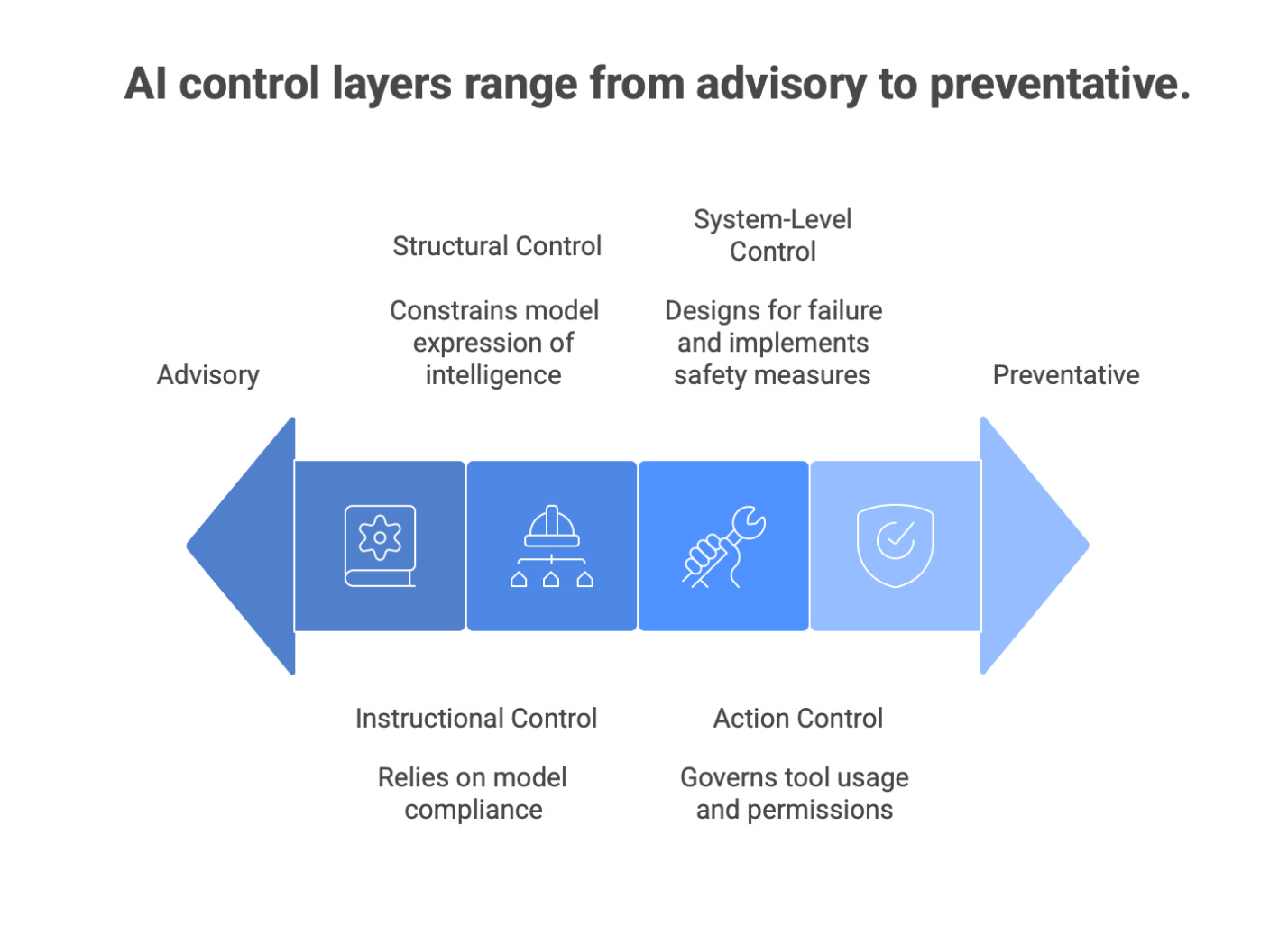
The Four Layers of AI Control
Effective AI control is layered.
Each layer compensates for the weaknesses of the one above it.
Most teams only implement the first layer.
Layer 1: Instructional Control (Necessary, Weak)
This includes:
system prompts
“do not” rules
policy instructions
Example:
Do not provide legal advice.
Refuse unsafe requests.
This layer depends entirely on model compliance.
Problems:
ambiguity
instruction decay in long contexts
inconsistent interpretation
failure under tool usage
Instructional control is advisory, not enforceable.
It should never be your primary defense.
Layer 2: Structural Control (Underused, Powerful)
Structural control constrains how the model expresses intelligence.
Examples:
fixed output schemas
mandatory planning steps
confidence fields
explicit refusal paths
Example schema:
{
“intent”: “”,
“plan”: [],
“final_answer”: “”,
“confidence”: 0.0,
“requires_human_review”: false
}
Why this matters:
structure limits improvisation
errors become detectable
downstream systems can react
This is where AI becomes controllable as a system, not just a response generator.
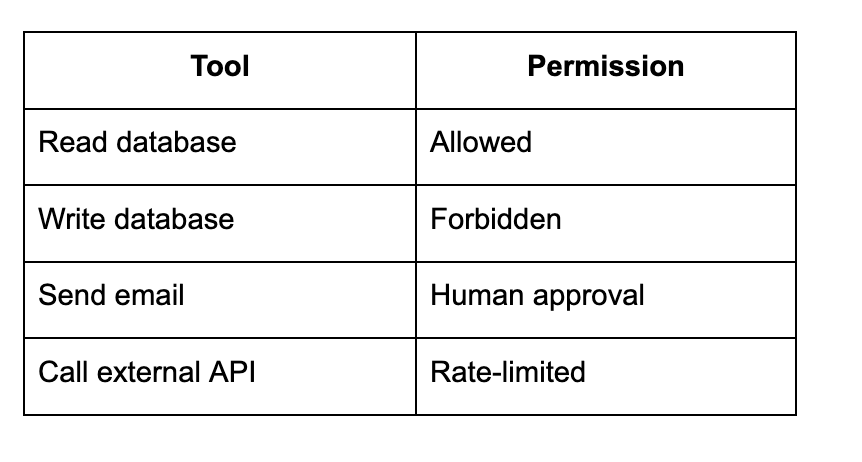
Layer 3: Action Control (Critical for Agents)
Once AI can act - not just respond - control becomes mandatory.
Action control governs:
which tools an AI can use
under what conditions
with what permissions
Think of tools as capabilities, not functions.
Example action policy:
Without action control:
agents optimize outcomes, not safety
small reasoning errors become real-world damage
blast radius expands rapidly
Most production failures in agentic AI happen here.
Layer 4: System-Level Control (Where Real Safety Lives)
System-level control assumes failure will happen and designs around it.
This includes:
evaluation gating
rollback mechanisms
kill switches
fallback routing
drift thresholds
Example logic:
if safety_score < threshold:
disable_agent()
route_to_human()
alert_team()
This layer does not trust the model to behave.
It treats intelligence like a volatile subsystem.
That mindset is the difference between demos and durable systems.
Control vs Alignment (A Critical Distinction)
Alignment asks:
“Does the AI want the right thing?”
Control asks:
“What happens if it doesn’t?”
Alignment is aspirational.
Control is operational.
You can deploy control today.
And without it, alignment failures are catastrophic.
Common AI Control Failures in Production
1. Overconfidence Failure
The model answers confidently despite low certainty.
Fix:
Confidence calibration + refusal thresholds.
2. Tool Escalation Failure
The agent uses powerful tools prematurely.
Fix:
Progressive permission escalation.
3. Looping Failure
Agent retries endlessly.
Fix:
Explicit stop conditions and retry caps.
4. Silent Drift
Behavior degrades over time.
Fix:
Behavior baselines + deviation alerts.
A Realistic Failure Scenario
An AI agent manages calendar scheduling.
For weeks, everything works.
Then:
input format changes
agent misinterprets availability
overlapping meetings get booked
No crash.
No exception.
Just unbounded behavior.
This is why “it worked yesterday” is meaningless in AI systems.
Control Is a Product Decision
Engineers implement control mechanisms.
But PMs and system designers must decide:
acceptable failure
autonomy limits
human intervention points
trust thresholds
If these decisions are not explicit,
control becomes reactive and inconsistent.
That’s how intelligent systems quietly become liabilities.
AI Control Maturity Model
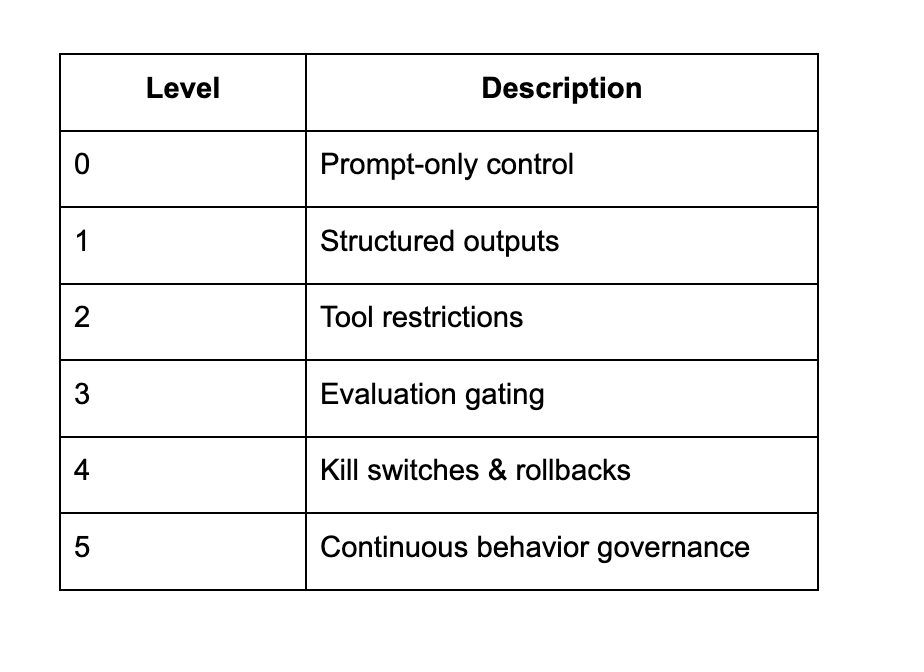
Most teams operate at Levels 0–2.
Serious AI systems must reach Level 4+.
Why Control Will Matter More Than Model Quality
Models are commoditizing.
Capabilities are converging.
Agents are proliferating.
What will differentiate systems is:
containment
recoverability
trust stability
Two teams using the same model
can ship radically different products
based entirely on control discipline.
That discipline compounds.
AI does not need to be perfectly intelligent.
It needs to be bounded, observable, and interruptible.
The future of AI belongs to teams who assume:
intelligence will fail
autonomy will misfire
confidence will be misplaced
…and design systems that catch failure before users do.
Control is not a constraint on AI.
It is what makes intelligence deployable at scale.
In the next generation of AI systems,
control will not be optional.
It will be the product.
Thank you for sharing the insight on uncontrollable ai and guardrails to put in the system before things go bad.
In the same manner based on real world system I learned hard way and now wrote a breakdown for AI safety and Security guide in this last article. Hope this also gives more insights to community
https://open.substack.com/pub/poojithamarreddy/p/building-secure-agentic-ai-a-product?r=3qhz95&utm_medium=ios&shareImageVariant=overlay
This is exactly what I've been saying! I worked on a support bot last year that kept escalating issues to managers without proper thresholds, and we ended up with VP-level staff handling password resets. The distinction between alignment and control really clicks for me because alignment is what we hope happens, control is what actually keeps things from going sideways. Most teams I see are still stuck at layer 1 thinking prompts will save them when they realy need structural guardrails.