
Retrieval vs Reasoning in AI
Why Hybrid Search+LLM Systems Outperform Pure Models

Why the future of AI isn’t bigger LLMs - it’s LLMs that can search, reference, and reason together.
There was a moment when people believed one gigantic model could do everything:
just scale GPT to 10 trillion parameters,
feed it the entire internet,
and let intelligence emerge.
We all know what happened next:
models plateaued.
Hallucination stayed.
Facts drifted.
Costs exploded.
And accuracy became impossible to guarantee.
A new realization spread across the industry:
LLMs are brilliant at reasoning but terrible at remembering facts.
Search systems are brilliant at recalling facts but terrible at reasoning.
The unlock?
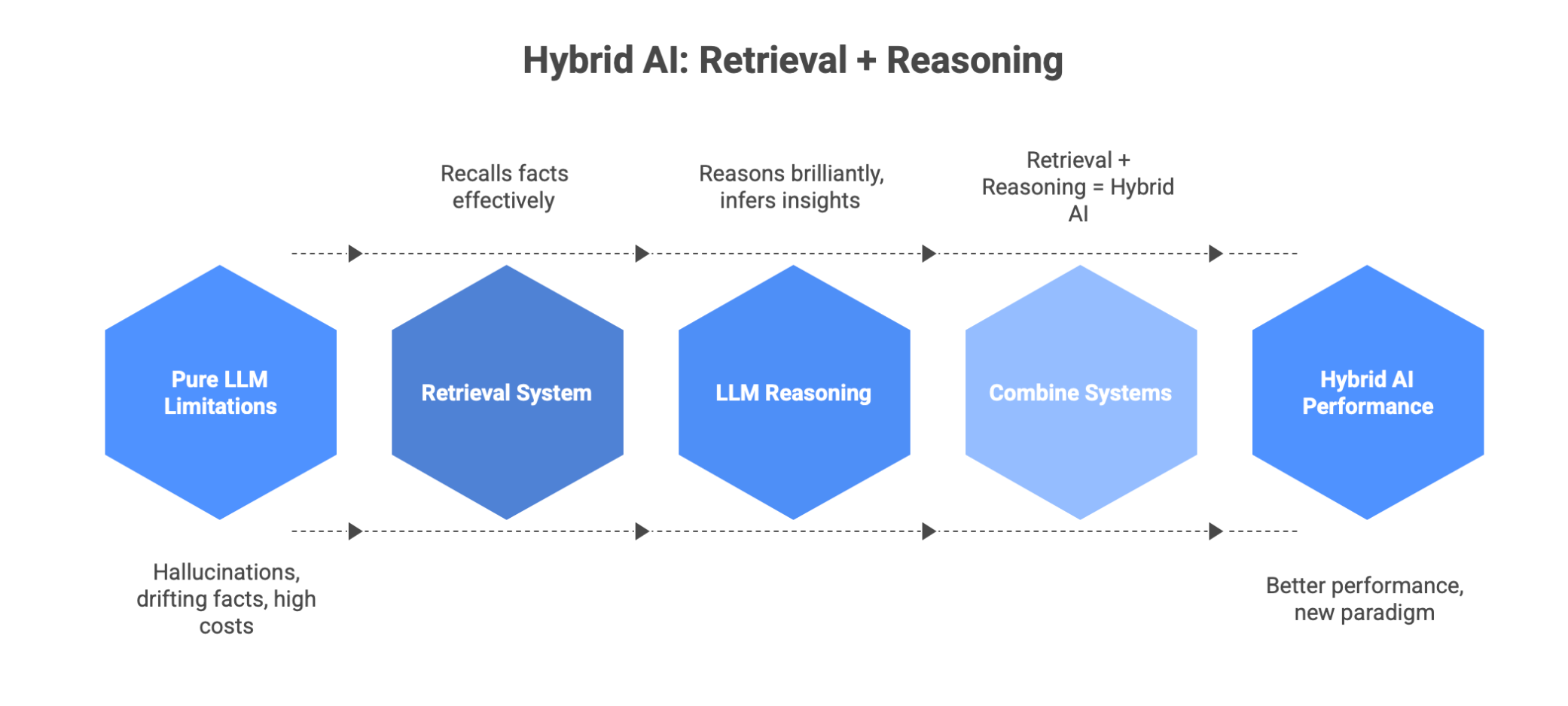
Hybrid AI architectures that combine both.
Retrieval + Reasoning.
Search + LLM.
Memory + Intelligence.
This isn’t just better performance, it’s a new architecture paradigm.
Why Pure LLMs Fail at Real-World Accuracy
LLMs were trained on fixed snapshots of the internet.
They produce fluent answers, but they:
hallucinate missing facts
invent citations
distort data
fail on niche queries
misremember rare information
The reason is structural:
an LLM does not store knowledge like a database.
It stores compressed language patterns.
Not exact information.
Not truth.
Not sources.
That’s why bigger models don’t solve hallucination:
They memorize more patterns, not more verifiable facts.
Why Retrieval Changes Everything
Retrieval systems (RAG, vector search, BM25, hybrid search)
do exactly what LLMs can’t:
They:
find real documents
match semantic meaning
provide citations
check claims
preserve sources
LLMs then reason over that retrieved information.
This combination drastically improves:
truthfulness
reliability
traceability
factual grounding
This is why every enterprise AI stack today includes retrieval.
THE CORE THESIS
Pure reasoning + Pure recall - combined intelligence.
Reasoning alone = hallucination.
Retrieval alone = no intelligence.
Retrieval + Reasoning = real AI.
The Mental Model: Human Brain Analogy
Your reasoning brain (frontal cortex)
does not store all memory.
It loads facts from external storage
your books, experiences, environment.
AI must do the same.
LLM vs Retrieval Strengths
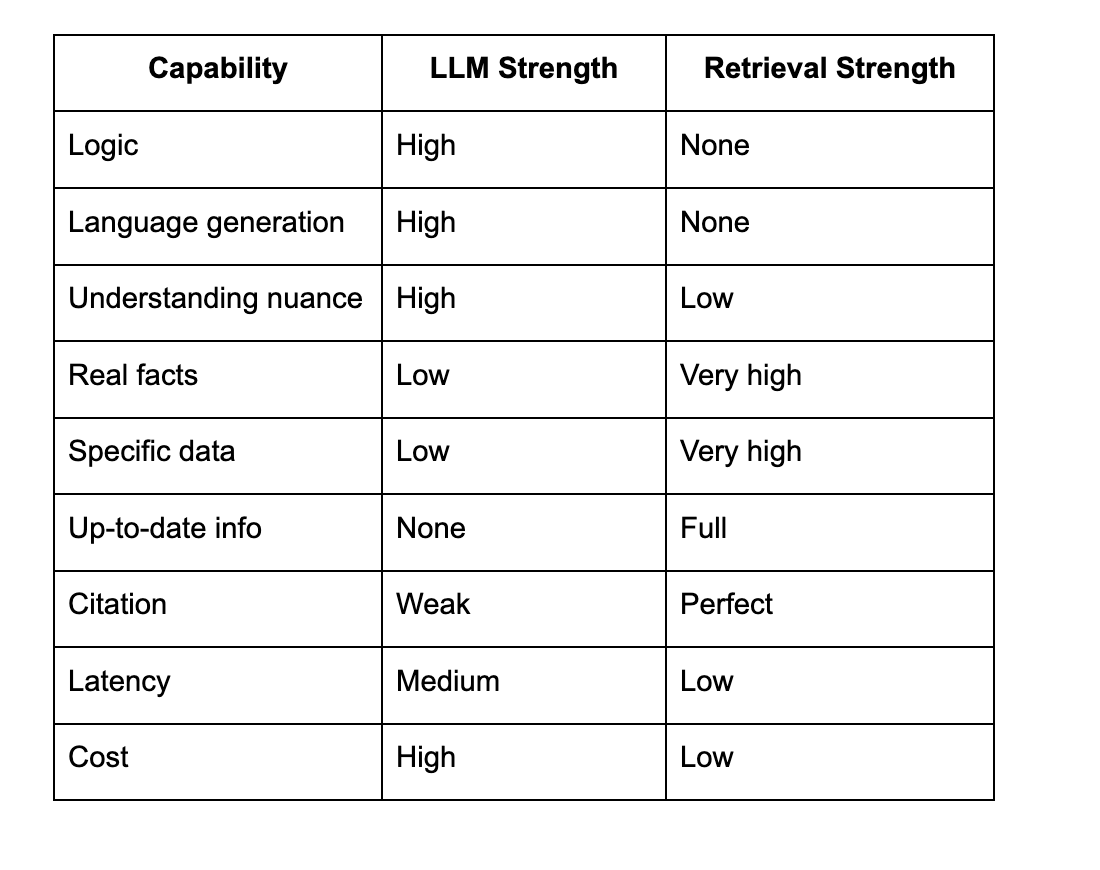
The hybrid wins.
Why Hybrid Beats Pure LLM Design
1 Hallucination collapses
Because answers are grounded in retrieved documents.
2 Accuracy skyrockets
Models speak from evidence, not probability.
3 Fresh knowledge enters instantly
No retraining needed.
4 Data security improves
Private corpus - private intelligence.
5 Cost drops
Use small LLM + powerful retrieval = massive savings.
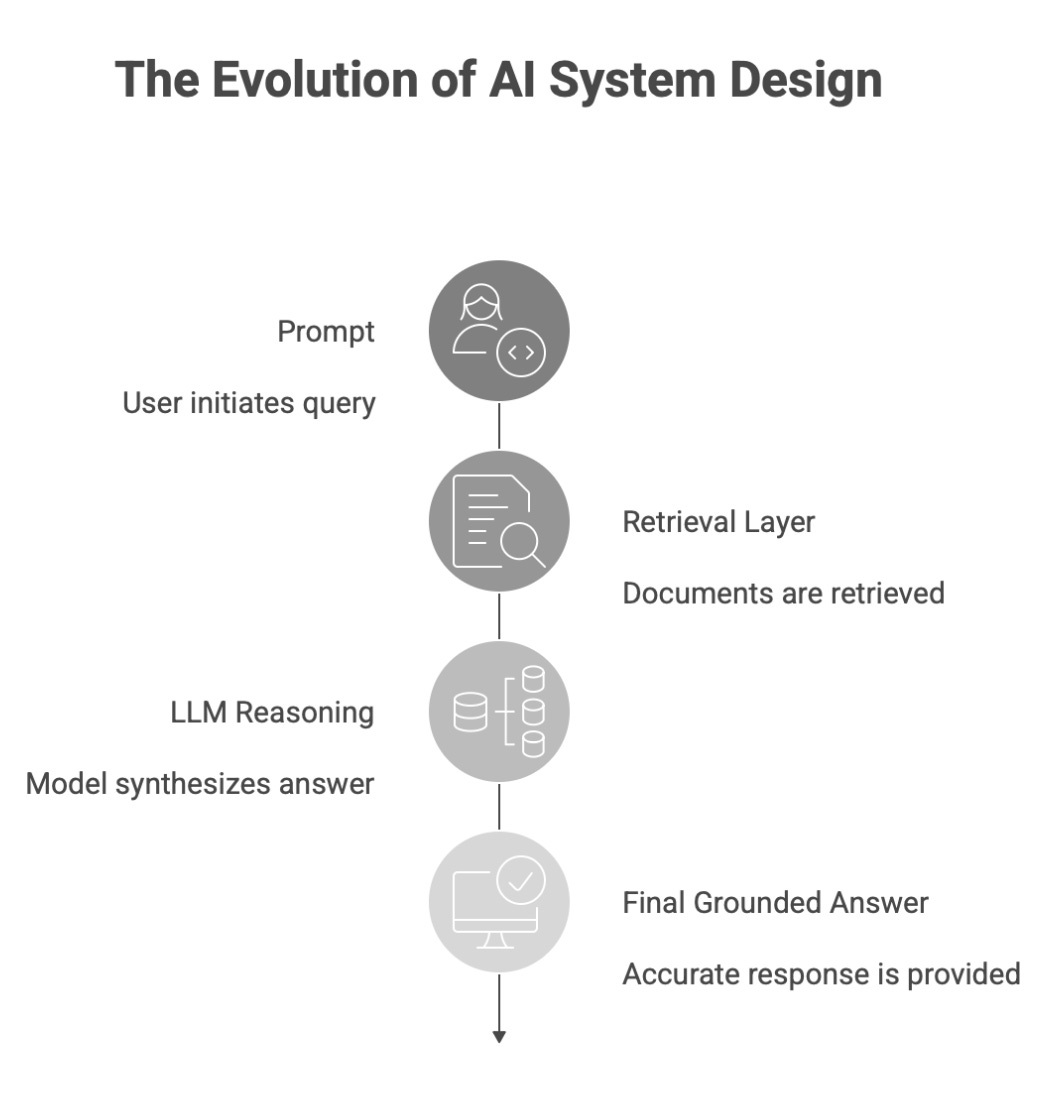
Architecture Overview
Here’s the structure behind most enterprise AI systems now:
User Query
↓
Retrieval Layer (vector search / hybrid search)
↓
Relevant documents
↓
LLM reasoning + synthesis
↓
Final grounded answer
There is no pure generation anymore.
ASCII: Why Retrieval Improves Behavior
Pure LLM flow:
Prompt → Model → Guess
Hybrid flow:
Prompt → Retrieve Evidence → Model Synthesizes → Answer
Focus shifts from guessing → referencing → reasoning.
But Wait - Why Not Train Bigger Models?
Because retrieval breaks scaling laws.
Training GPT-7 to store every document forever is:
impossible
unnecessary
expensive
unstable
legally risky
Retrieval externalizes memory.
Forever scalable.
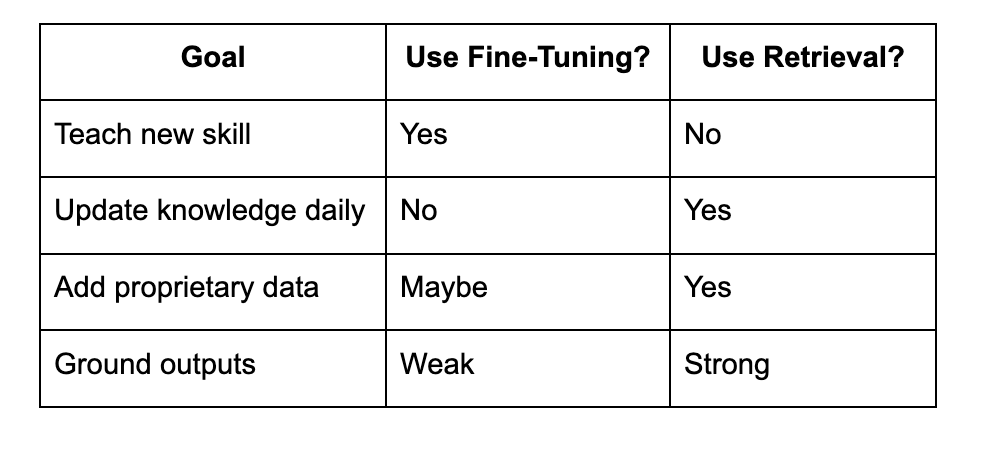
Why Retrieval Beats Fine-Tuning
Fine-tuning teaches new behavior, not new information.
Retrieval inserts fresh knowledge directly.
RAG Example: How Hybrid Improves Output Quality
Prompt:
“Summarize latest 2026 Tesla earnings.”
🔥 Pure LLM answer: hallucination
🔥 Hybrid answer: source-grounded, factual
This alone proves the architectural shift.
Code Example: Mini Retrieval Pipeline
from sentence_transformers import SentenceTransformer
from sklearn.neighbors import NearestNeighbors
import numpy as np
docs = [
“Paris is the capital of France.”,
“Berlin is the capital of Germany.”,
“Tokyo is the capital of Japan.”
]
query = “capital of Germany?”
model = SentenceTransformer(’all-MiniLM-L6-v2’)
embeddings = model.encode(docs)
query_embedding = model.encode([query])
nn = NearestNeighbors(n_neighbors=1).fit(embeddings)
idx = nn.kneighbors(query_embedding, return_distance=False)
print(docs[idx[0][0]])
The model retrieves correctly:
“Berlin is the capital of Germany.”
LLM reasoning would then produce explanation + narrative.
Why This Hybrid Trend Blew Up in 2025–2026
Three forces collided:
1 Enterprises need correctness
Financial, medical, legal systems require truth.
2 AI cost crisis
LLMs are expensive to run.
3 Hallucination lawsuits
Real legal exposure emerges.
Hybrid solves all three.
Future: Retrieval + Reasoning - AGI Architecture
AGI needs memory.
No entity becomes intelligent by memorizing static text.
It must access external dynamic information.
Hybrid enables:
world-awareness
stateful intelligence
continuous updating
memory loops
knowledge bases
tool use
planning
verification
multi-step thinking
Where Hybrid Wins Today
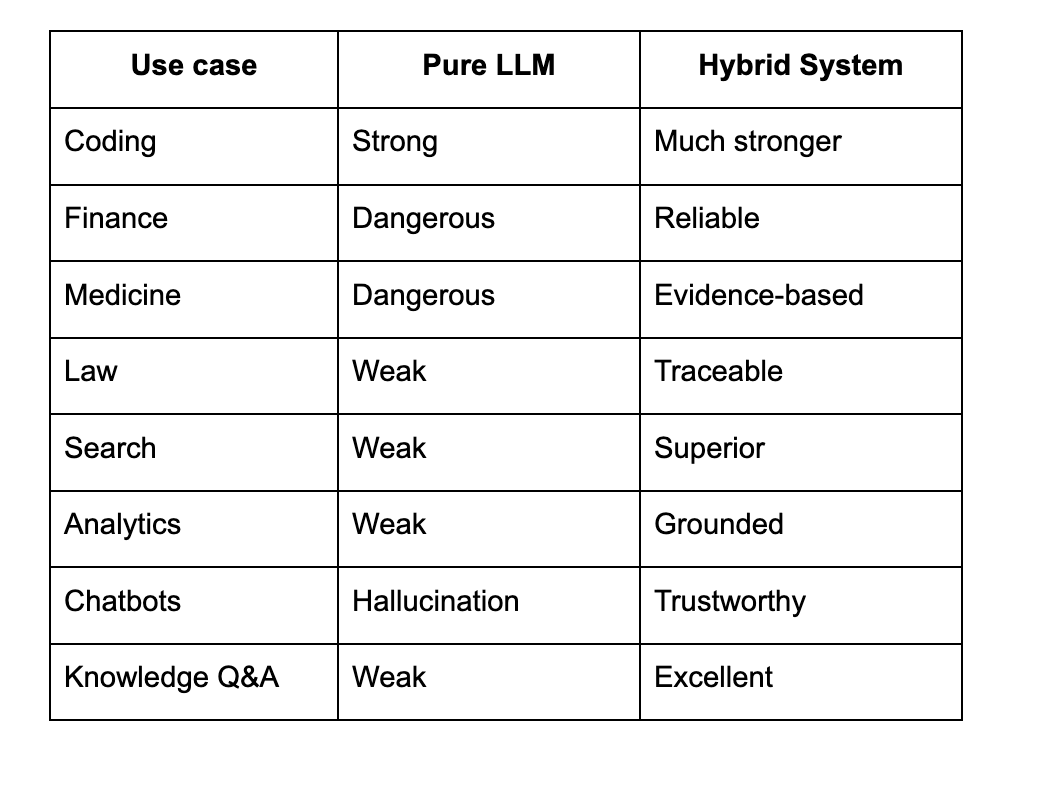
Hybrid = deployment-ready AI.
Why Hybrid Aligns With Human Intelligence
Humans retrieve constantly:
Books.
Notes.
Memories.
Wikipedia.
Experience.
Brain doesn’t store everything
it stores compression, and retrieves detail externally.
That is hybrid.
Why OpenAI, Meta, Anthropic, Google All Converged
Every major roadmap shows the same direction:
OpenAI: Retrieval + tool use
Anthropic: Constitutional + retrieval
Meta: RAG pipeline integration
Google: Multi-search + Gemini reasoning
Hybrid is not optional
it’s inevitable.
Where Hybrid Systems Still Fail
Three weaknesses remain:
1 Bad retrieval - bad answer
Quality depends on corpus.
2 Slow pipelines
Latency from search layers.
3 Evaluation complexity
Harder to test than pure models.
But all improving fast.
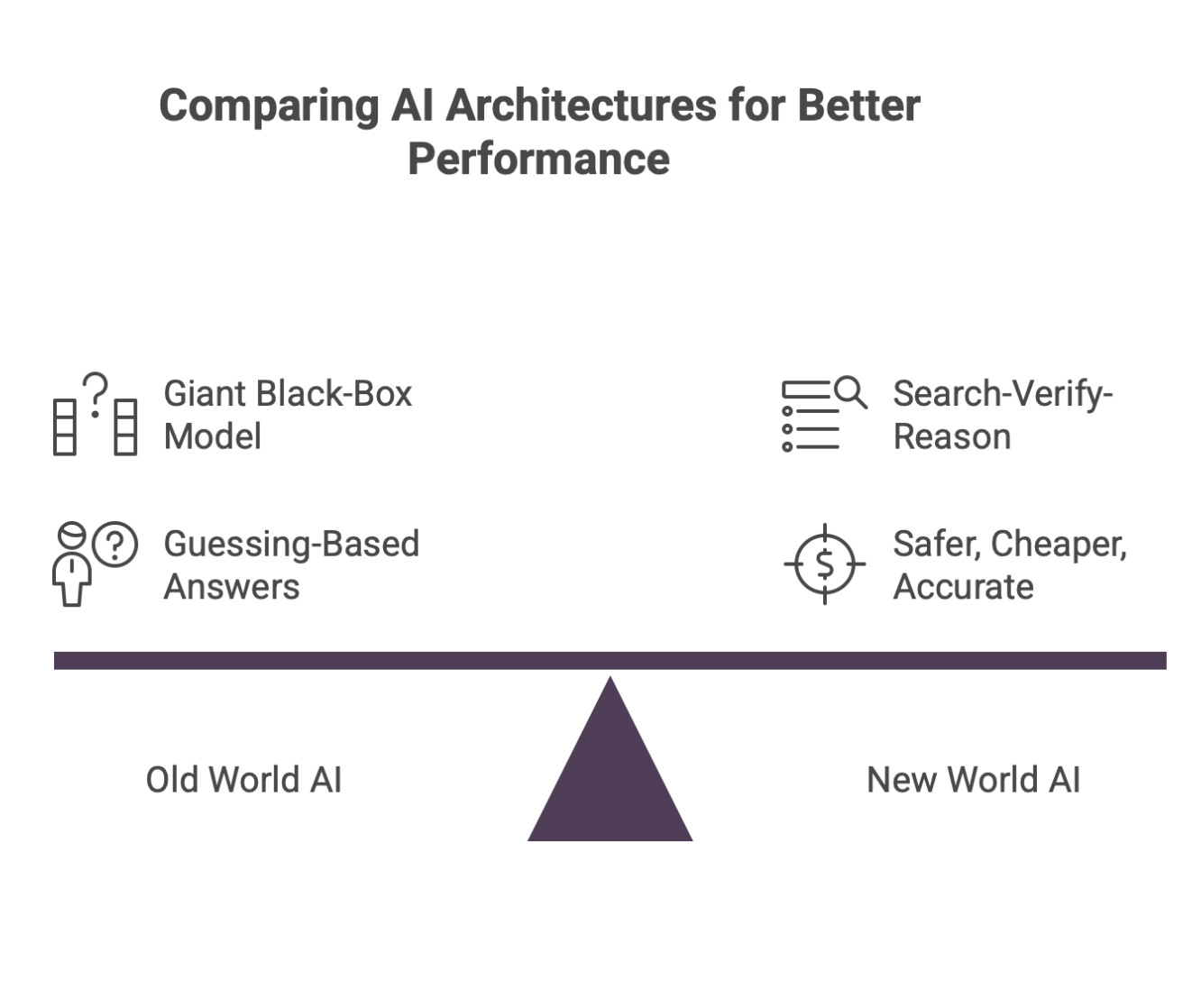
Zoom Out: Why This Matters
The AI world is dividing into two architectures:
Old World
One giant black-box model guessing.
New World
Search - verify - reason - answer.
The second is:
safer, cheaper, and more accurate.
The Big Idea: Reasoning Is Not Knowing
LLMs are excellent thinkers.
They are terrible librarians.
Retrieval systems are perfect librarians.
They cannot think.
Together - they become intelligence.
The future winners in AI
won’t be the companies with the biggest models.
They will be the companies that:
retrieve knowledge well
reason over it brilliantly
verify answers at scale
and combine search + intelligence
Hybrid is not a patch.
It’s the new architecture layer.
The age of pure LLMs is ending.
The age of retrieval + reasoning has begun.
Hybrid systems are where the real work gets done.
Retrieval keeps you grounded, reasoning lets you adapt.
Most organizations are still figuring out which problems need which approach: https://vivander.substack.com/p/something-shifted-when-i-read-openais
Framing retrieval as accountability, not just accuracy, shifts the whole conversation.
The real value isn't speed or cost savings, it's that the system can now explain where it got its answer from.
This changes how teams trust AI outputs and actually start building around them.