
The Information Bottleneck in AI
How Compression Creates Intelligence

Why the smartest AI systems don’t remember everything- they remember only what matters
Every conversation around AI today sounds the same:
“Bigger models are coming.”
“GPT-5 will change everything.”
“Parameter count equals intelligence.”
The industry worships size.
More data - more epochs - more GPU - more tokens.
Size is the headline.
Scale is the narrative.
Hardware is the obsession.
But look beneath the hype, and a quieter truth is emerging:
AI doesn’t become intelligent by storing more.
AI becomes intelligent by forgetting more.
This is the world of the Information Bottleneck
and once you understand this principle,
LLMs, embeddings, hallucination, memory, data efficiency,
and even AGI start to make sense in a new way.
This blog explains the entire theory:
how it works, why it works, why it changes model design,
why it explains hallucination,
and why the future of AI isn’t size
it’s compression.
The Counterintuitive Idea: Intelligence Comes From Losing Information
In 1999, Israeli physicist Naftali Tishby proposed a radical thought:
If a learning system wants to make accurate predictions,
it must throw away most of the information it receives.
It sounds absurd.
Schools teach the opposite:
learn more, store more, memorize everything.
But biology disagrees.
Brains forget.
Consciousness compresses.
Memory decays into meaning.
Evolution didn’t produce animals that remember every detail.
Evolution produced animals that remember only the patterns
needed to survive.
AI is now replicating that strategy.
Why Raw Data Is Useless to Intelligence
When a model reads a sentence:
“The little boy kicked the blue ball across the street.”
The raw data contains:
The exact shade of blue
The ordering of letters
The capitalisation
Token IDs
Word shapes
Spacing
Punctuation
Sentence length
A naive system would keep all of it.
A smart system keeps only:
boy - kicks - ball - across - street
(actor - action - object - direction - location)
Meaning survives.
Detail dies.
That death of detail
is the source of intelligence.
The Exact Math Behind the Theory
Information Bottleneck tries to maximise:
I(Z;Y) - useful information kept
and minimise:
I(Z;X) - useless information from input
Where:
X = input
Y = target
Z = compressed representation
In simple words:
Z must keep what predicts Y
and discard everything else from X.
This explains deep learning at scale.
Bottleneck vs Memorization
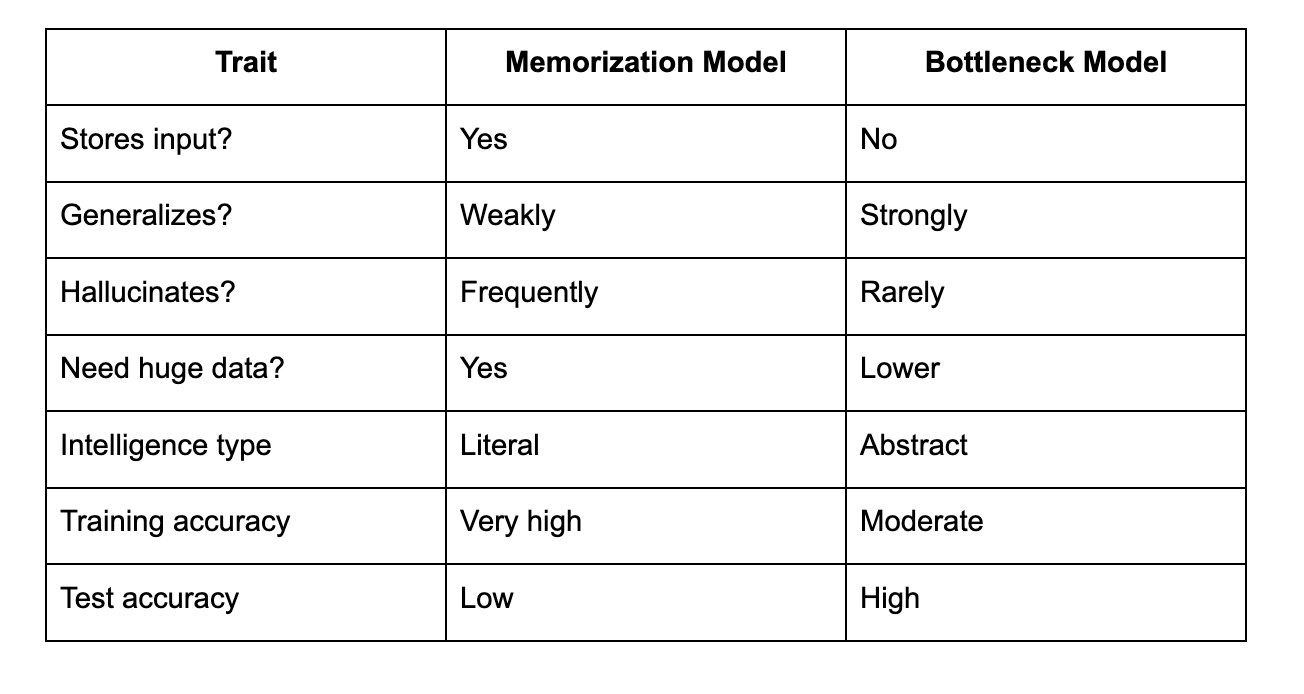
This is why test loss matters more than train loss.
Why Deep Networks First Memorize, Then Forget
Researchers noticed a striking pattern:
neural networks go through two phases during training.
Phase 1 - Fitting
The model memorizes most data.
Train accuracy climbs.
Loss shrinks.
But test accuracy barely improves.
Phase 2 - Compression
Suddenly the model begins throwing information away:
latent structure emerges
clusters sharpen
semantic categories form
Test accuracy shoots up.
This aligns perfectly with human learning:
we first copy, then internalize, then abstract.
ASCII TRAINING CURVE
Accuracy ↑
│
│ ┌─────────────── Plateau
│ ┌─┘
│ ┌─┘
│ ┌─┘
└──────────────────────────→ Training Time
Fit Phase Compress Phase Generalization
This pattern repeats across:
CNNs, RNNs, Transformers, Diffusion models.
Why Compression Builds Abstraction
The brain does not store every memory.
It stores compressed templates:
“dogness”
“anger”
“gravity”
“sarcasm”
“triangle”
You never remember every chair you’ve seen.
You remember the concept chair.
Compression - category formation - abstraction.
Neural networks form:
embedding clusters
vector manifolds
semantic gradients
These are compressed abstractions.
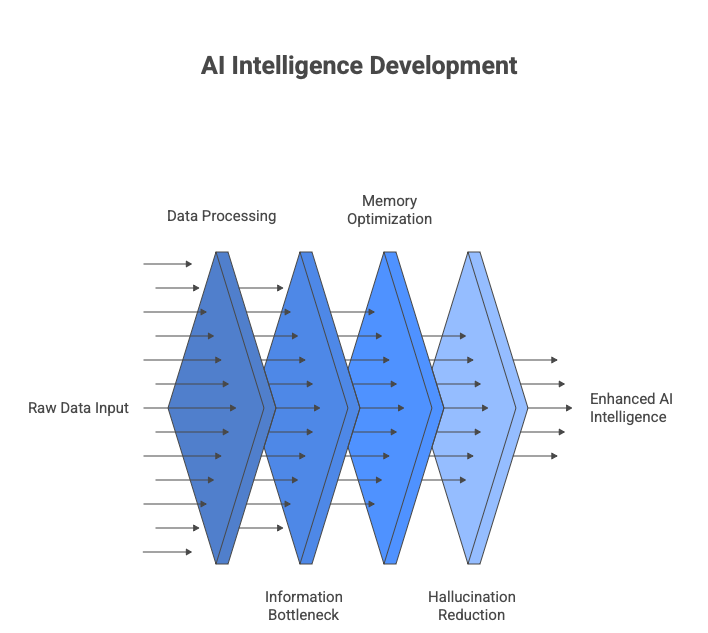
Where Compression Operates in AI
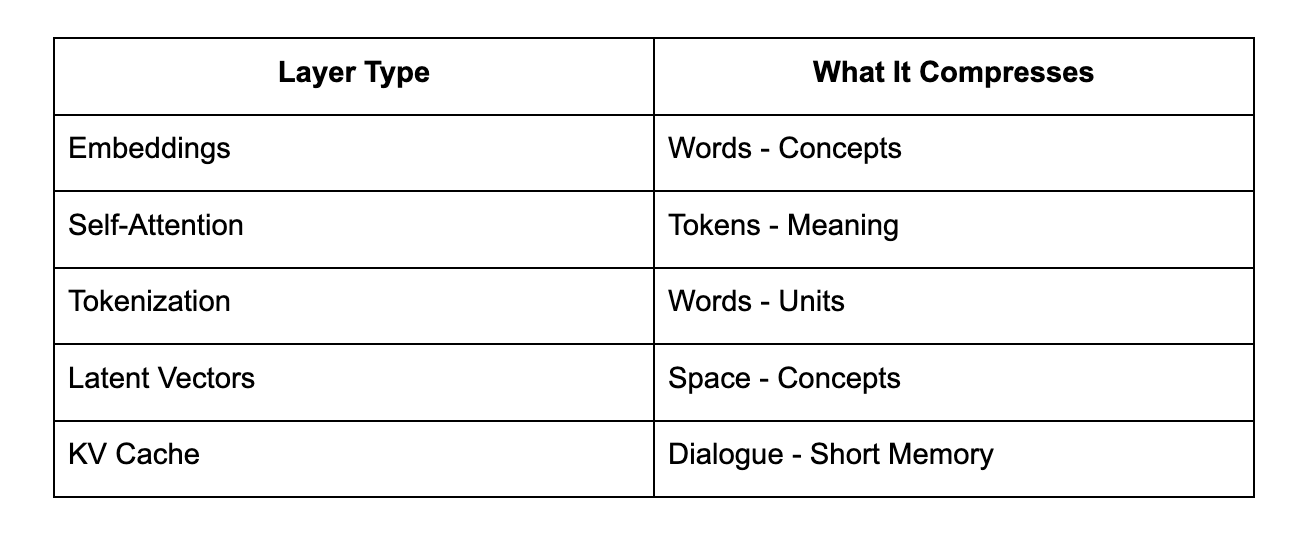
Every step reduces dimensionality.
Compression Eliminates Hallucination
Hallucination happens when:
representation loses meaning structure
and compression collapses too far.
When IB is tuned correctly:
models hallucinate less
not because they “try harder”
but because they store better abstractions.
CODE EXAMPLE: Showing IB Power With PCA
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
X, y = load_digits(return_X_y=True)
pca = PCA(n_components=20)
X_reduced = pca.fit_transform(X)
clf = LogisticRegression(max_iter=5000)
X_train, X_test, y_train, y_test = train_test_split(X_reduced, y)
clf.fit(X_train, y_train)
print(”Accuracy:”, clf.score(X_test, y_test))
90% of data lost.
Accuracy ↑
Generalization ↑
Compression creates intelligence.
Why GPT Models Are Compression Engines
LLMs don’t store language literally.
They store meaning.
That’s why LLMs can:
predict unseen sentences
translate without dictionaries
generate poetry
explain physics
They compress human history
into a conceptual latent universe.
GPT models store
density fields of knowledge - not books.
Latent Space Geometry - Where Intelligence Lives
Latent space is multidimensional meaning geometry.
Concepts like:
cat
tiger
lion
form clusters
because they share meaning vectors.
That clustering is compression.
Without compression - chaos.
Latent Dimensionality vs Accuracy Trend
Accuracy ↑
│ *
│ *
│ *
│ *
│ *
└──────────────────────────→ Dimensionality Reduction
As dimensionality shrinks thoughtfully,
accuracy increases.
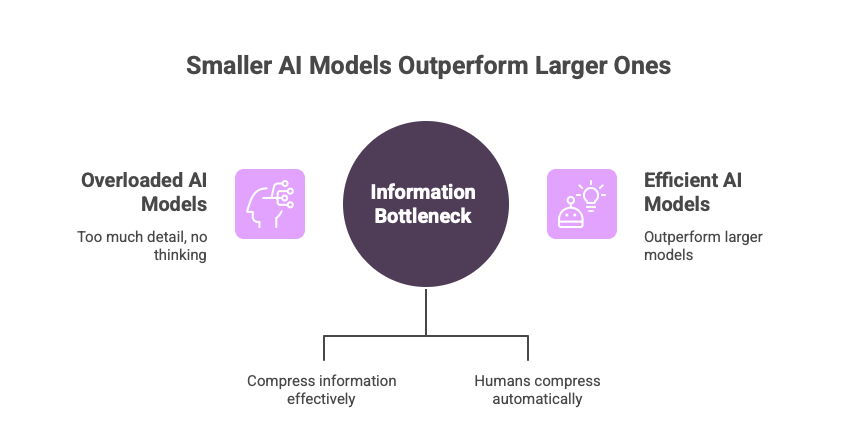
Why New AI Models Are Getting Smaller
Look at the trend:
Qwen 2.5
Meta Llama-3
Gemini Flash
Phi models
Mixtral
Nemotron MoE
These outperform much larger models.
Why?
Better compression architecture.
The bottleneck beats brute force.
Information Bottleneck Is the Blueprint of Human Thought
Humans fail when overloaded:
too much detail - no thinking.
We compress automatically:
events - stories
people - identities
visuals - symbols
emotions - categories
Without forgetting,
we drown.
Memory = Stored Compression
Humans remember
the abstraction of a trauma,
not the precise light photons
that hit the retina.
AI must do the same.
That means:
future LLM breakthroughs will come
from improved compression layers,
not trillion-token training.
Why the Bottleneck Solves the Cost Crisis
GPU economics are brutal.
Compression unlocks:
distillation
pruning
4-bit models
quantization
sparse mixtures
Soon, 4B models will outperform 70B models
because compression beats brute memory.
The Coming Shift: Bottleneck - AGI
AGI requires:
concept space
abstraction
memory
forgetting
hierarchical compression
GPT-4 already shows early signs:
it generalizes beyond training samples.
This is IB at scale.
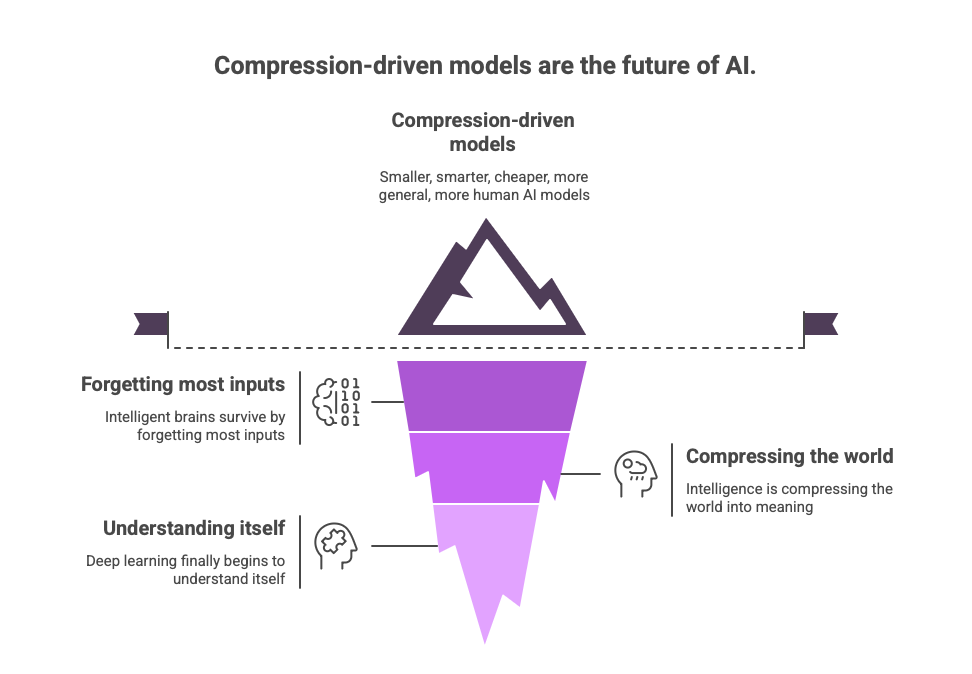
The Information Bottleneck isn’t a theory about math.
It’s a theory about reality:
Intelligence isn’t remembering the world
it’s compressing the world into meaning.
Everything intelligent brains, animals, society, evolution
survives because it forgets most inputs.
The same will be true for AI.
The future belongs to compression-driven models:
smaller
smarter
cheaper
more general
more human
This is not the end of deep learning.
It is the moment deep learning
finally begins to understand itself.
AI becomes intelligent by forgetting more.
The compression principle explains why smaller, focused implementations often outperform massive general models.
If you're thinking about what this means for your team's AI strategy: https://vivander.substack.com/p/something-shifted-when-i-read-openais
The idea that intelligence is compression, not memorization, completely reframes how we should think about AI success.
Most orgs are still measuring AI like they measure databases: how much can it hold?
The real question is how well does it forget what doesn't matter.