
The Invisible AI Stack: LangSmith, Weights & Biases & OpenAI Evals Explained
What separates AI products that actually work from ones that quietly fail, and the tools helping builders close that gap.

There’s a version of AI product development that most people don’t talk about enough.
It’s not the glamorous part. Not the moment you plug in GPT-4 and watch it generate something impressive. It’s the part that comes after. The part where your model starts behaving unexpectedly in production. Where a prompt that worked perfectly in testing suddenly halts, hallucinates, or misses the mark entirely. Where you have no idea why.
That’s the part where most AI teams quietly suffer.
The secret of building with LLMs is that without the right infrastructure around your model, you’re essentially flying blind. You’re shipping a system whose internal logic you can’t see, can’t trace, and can’t measure in any meaningful way.
And yet, a huge number of teams are doing exactly that.
This article is about the tools that fix that. The invisible AI stack that lives between your model and your user: LangSmith, Weights & Biases, and OpenAI Evals. We’ll break down what each of them does, why they matter, and how to think about using them together.
The Problem of AI Without Observability
You’ve built a customer support bot. It handles thousands of queries a day. On average, it seems fine. But somewhere in that volume, it’s giving wrong answers. You don’t know which queries are failing. You don’t know whether it’s the prompt, the retrieved context, or the model itself. You have no tracing, no replay, no structured feedback loop.
This is the observability problem in AI, and it’s more common than you’d think.
Traditional software has mature debugging tools. You can trace a bug to a specific line of code. With LLMs, the logic is probabilistic, context-dependent, and spread across prompts, embeddings, retrieval layers, and model calls. There is no single “line of code” to point to.
Without observability, you can’t improve what you can’t see.
The tools we’re about to discuss exist specifically to solve this. Each one approaches the problem from a different angle, and together they form a stack that gives AI teams the visibility and control they need for serious AI product development.
The Invisible AI Stack: What It Is and Why It Matters?
When people think about the “AI stack,” they usually mean the visible layer: the model, the API, maybe a vector database or a RAG pipeline.
But there’s a second stack operating beneath the surface, one focused entirely on evaluation, monitoring, experimentation, and tracing. This is the invisible AI stack.
It’s “invisible” not because it doesn’t matter, but because it rarely gets discussed in launch posts or product demos. It’s the infrastructure that keeps AI systems honest and improvable after they leave the lab.
Think of it this way: the visible stack is what makes your AI do something. The invisible stack is what makes it keep doing it well.
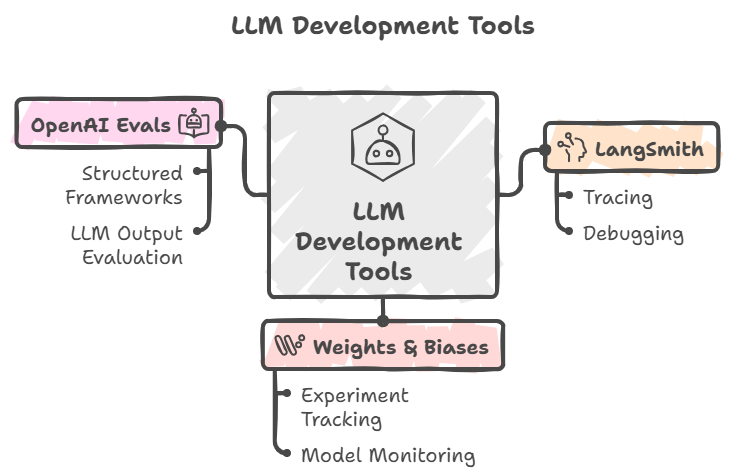
The three tools that anchor this layer are:
LangSmith: tracing and debugging for LLM chains
Weights & Biases (W&B): experiment tracking and model monitoring
OpenAI Evals: structured evaluation frameworks for LLM outputs
Each one solves a distinct problem. Together, they form the backbone of any serious building scalable AI systems effort.
LangSmith: Seeing Inside Your LLM Chains

If you’ve ever built anything with LangChain, or even a custom multi-step LLM pipeline, you know how quickly things get opaque. A single user request might trigger a cascade: a retrieval call, a reranking step, a prompt assembly, and finally a model completion. When something goes wrong, where do you even start?
LangSmith is built to answer that question.
Developed by the team at LangChain, LangSmith is an observability and debugging platform specifically designed for LLM applications. At its core, it gives you full trace visibility into every step of your AI chain.
Here’s what that looks like in practice. When a user submits a query to your application, LangSmith captures the entire execution path: every prompt sent to the model, every tool call made, every piece of retrieved context, and every output returned. You can replay these traces, inspect individual steps, and pinpoint exactly where a chain deviated from expected behavior.
This is what debugging LLMs actually looks like when you have the right tools.
Beyond debugging, LangSmith supports dataset curation and prompt testing workflows. You can flag problematic traces, add them to evaluation datasets, and run regressions against them whenever you change a prompt or swap a model version. This makes prompt iteration feel much more like software engineering and less like guesswork.
For teams working on prompt engineering strategies, LangSmith is arguably indispensable. It transforms what would otherwise be a trial-and-error process into something traceable, repeatable, and auditable.
Weights & Biases: The Experiment Tracker That Scales With You
Weights & Biases, commonly called W&B or “Wandb,” has been a staple in the ML research world for years. If LangSmith is about tracing what your LLM does, W&B is about tracking what your model is, across every version, every run, and every configuration change.
The core value proposition: reproducibility and comparison.
When you’re running AI experimentation workflows, one of the hardest things to maintain is a clear record of what you tried, what worked, and why. Teams often run dozens of experiments, tweaking learning rates, swapping embedding models, and changing chunking strategies, then lose track of which configuration produced which result.
W&B solves this by logging all of it: hyperparameters, evaluation metrics, model artifacts, training curves, and system hardware utilization. Every run is versioned, searchable, and comparable side-by-side. You can look at a table of ten experiments and immediately see which configuration produced the highest accuracy on your held-out test set.
Beyond tracking, W&B offers Weave, their newer suite specifically designed for LLM applications. Weave handles tracing for LLM calls, evaluation pipelines, and prompt versioning in a way that integrates naturally with the W&B ecosystem. If you’re already using W&B for ML work and you’re now building LLM-powered features, Weave gives you continuity without requiring you to rebuild your instrumentation from scratch.
W&B also shines in collaboration. Shared dashboards, report generation, and team-level access controls make it easier for AI teams to communicate findings internally. Instead of screenshotting results and pasting them into Slack, teams can share a W&B report that captures the full context of an experiment: methodology, results, and next steps all in one place.
The teams that scale AI products successfully tend to treat every model iteration like a proper experiment. W&B is what makes that discipline sustainable.
One area where W&B particularly excels is fine-tuning workflows. If you’re moving beyond prompting and into actually training or fine-tuning models, W&B is the standard tool for tracking those runs. It integrates with Hugging Face, PyTorch, JAX, and most major frameworks with minimal setup.
OpenAI Evals: Structured Evaluation for Language Model Outputs

Evaluation is arguably the hardest unsolved problem in applied AI. How do you know if your model is actually getting better? How do you measure output quality in a way that’s reliable, consistent, and doesn’t require a human to review every single response?
OpenAI Evals is the framework OpenAI built to address this problem, and then open-sourced for the community.
At its simplest, OpenAI Evals lets you define evaluation tasks and run your model against them systematically. You write an eval, which specifies the input, the expected behavior, and the scoring criteria, and then run it against any model or prompt configuration you want to test.
The framework supports several evaluation patterns. Match evals check whether the model’s output matches an expected answer exactly, which is useful for factual Q&A. Model-graded evals use a second LLM to assess the quality of the first model’s outputs, a surprisingly effective approach for open-ended tasks where there’s no single correct answer. Custom evals let you define your own scoring logic for domain-specific criteria.
What makes OpenAI Evals particularly powerful is its role in regression testing. Every time you change a prompt, upgrade a model version, or modify your retrieval logic, you want to know whether your system got better or worse on the tasks that matter. Running your eval suite after every significant change gives you that answer in a structured, reproducible way.
For teams serious about LLM evaluation techniques, this is the difference between guessing whether things improved and knowing.
One underrated use of OpenAI Evals: identifying the specific failure modes your model exhibits, not just its average performance.
Average scores can mask a lot of variance. A model that scores 85% overall might be nearly perfect on common cases but catastrophically wrong on rare but important edge cases. Evals help you surface those failure modes systematically rather than stumbling across them in production.
How These Three Tools Work Together
Each tool solves a distinct problem, but their real power comes from how they complement each other.
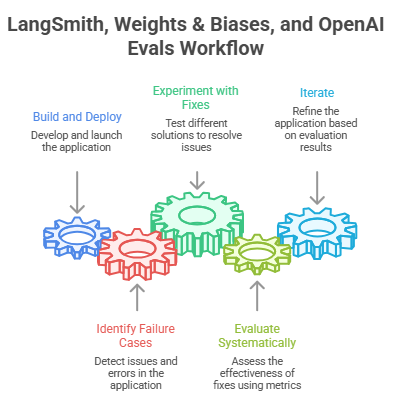
Here’s a simplified workflow that illustrates how they fit together:
Step 1: Build and deploy. Your LLM application goes live. LangSmith starts capturing traces of every interaction: prompts, retrieval steps, model outputs, and latency.
Step 2: Identify failure cases. You review traces in LangSmith and notice patterns. Certain query types consistently produce poor outputs, a retrieval step is returning irrelevant context, or a particular prompt formulation causes the model to go off-track. You tag these traces and add them to a curated evaluation dataset.
Step 3: Experiment with fixes. You hypothesize that a different prompt structure or a different retrieval strategy might help. You run experiments using W&B to track each configuration, logging prompt versions, retrieval settings, and output quality metrics side by side.
Step 4: Evaluate systematically. You codify the failure cases from Step 2 into an OpenAI Evals suite. Now you can run this suite against every new configuration you test, giving you a structured signal on whether your changes are actually fixing the problem.
Step 5: Iterate. You find a configuration that performs better on your eval suite, deploy it, and continue monitoring with LangSmith. The cycle repeats.
This loop, trace, experiment, evaluate, deploy, is the foundation of mature AI experimentation workflows. But it’s what separates teams that consistently ship better AI products from those that iterate based on gut feel.
Common Mistakes Teams Make
Even with these tools available, teams fall into predictable traps.
Treating evals as a one-time exercise. Running evaluations once during development and never again is like testing your code once before shipping and disabling all future tests. Models drift. Prompts get updated. Retrieval pipelines change. Your eval suite needs to run continuously.
Evaluating only on average performance. As mentioned earlier, aggregate metrics hide distributional problems. Always look at per-category breakdowns and examine your worst-performing examples explicitly.
Not investing in good evaluation data early. The quality of your evals is only as good as the data behind them. Investing time upfront in curating a diverse, representative set of test cases pays enormous dividends later. Rushing this step means your evals will tell you very little.
Using LangSmith only for debugging, not proactive monitoring. LangSmith isn’t just a fire extinguisher. It’s also a smoke detector. Setting up alerts and reviewing traces regularly, not just when something breaks, surfaces slow degradation before it becomes a crisis.
Skipping W&B because the team is “just prompting.” Even if you’re not training models, you’re still running experiments. Different prompts, different retrieval strategies, different chunking parameters are all experiments. Treating them as such, with proper logging and comparison, accelerates your iteration speed significantly.
An Actionable Playbook for Getting Started
You don’t need to implement all three tools at once. Here’s a sensible onboarding sequence:
Week 1: Instrument with LangSmith. Add LangSmith tracing to your existing application. Spend the first week simply reviewing traces. You’ll almost certainly find things you didn’t know were happening. Tag interesting cases, good and bad, as you go.
Week 2: Build your eval dataset. Take the tagged cases from Week 1 and formalize them into an evaluation set. Aim for at least 50 to 100 diverse examples that represent both typical use and edge cases.
Week 3: Set up OpenAI Evals. Codify your evaluation criteria and run your first systematic evaluation pass. Establish a baseline score that you can track over time.
Week 4: Add W&B for experiment tracking. Start logging your prompt experiments, configuration changes, and eval scores in W&B. Even simple logging here adds enormous clarity over time.
Ongoing: Run your eval suite on every meaningful change. Treat this like a CI/CD check for your AI system. If a change causes your eval scores to drop, investigate before shipping.
This is the foundation of serious, scalable AI product development. It’s not overly complex, but it requires intentionality. Most teams that “just ship and see” eventually hit a wall where they can’t tell what’s working and why.
Key Takeaways
The invisible AI stack is as important as the visible one. The model you choose matters far less than how well you can observe, evaluate, and improve it over time.
LangSmith gives you eyes inside your chains. It turns opaque LLM pipelines into traceable, debuggable, improvable systems. Use it for tracing, dataset curation, and continuous monitoring.
Weights & Biases brings scientific rigor to your experiments. Whether you’re tuning prompts or fine-tuning models, proper experiment tracking is what separates systematic improvement from random walks.
OpenAI Evals makes quality measurable. Without structured evaluation, you’re guessing whether things improved. With it, you know, and you know why.
The real magic is the loop they enable together. Trace with LangSmith. Experiment with W&B. Evaluate with OpenAI Evals. Ship with confidence. Repeat.
The most successful AI teams don’t just move fast. They move fast and build feedback loops that let them course-correct quickly when things go wrong. That combination, speed plus visibility, is what the invisible AI stack makes possible.
Start small. Instrument one thing. Build one eval. Track one experiment.
The invisible work is where the real AI products are built.
If you found this useful, consider exploring more on building scalable AI systems and LLM evaluation techniques. There’s a lot more depth to go into each of these tools individually.